

초오오오오오짜개발자의낙서장
밑바닥부터 만들면서 배우는 LLM- ch01 본문
- chat gpt와 같은 대규모 언어 모델은 심층 신경망 모델(deep neural network) 이다
- 이 모델들은 자연어 처리(natural language processing)에 큰 기여를 했다.
- LLM이 등장하기 전까지는 간단한 패턴 인식 모델로 감지했다
- 다양한 상황( 지시를 분석, 맥락을 이해) 등을 수행하지 못했다.
- LLM은 사람의 언어를 이해한다.
- 여기서 이해는 사람의 이해가 아닌 일관성 있고 맥락에 맞도록 텍스트를 처리, 생성 하는것
- 딥러닝의 발전으로 대규모 훈련 덕분에 LLM은 사람 언어의 미묘함과 문맥 정보를 깊이 이해한다.
- LLM은 텍스트 번역, 감성 분석, 질문 답변 등 NLP 작업에서의 성능이 크게 발전함.
현대 LLM 과 이전 NLP 모델과의 차이
- 이전 NLP 모델은 텍스트 분류, 언어 번역 등과 같은 특정 작업에 맞게 고안
- LLM은 다양한 작업을 처리 가능.
- LLM의 기반인 트랜스 포머 구조와 방대한 훈련 데이터가 존재.
이 책의 주요 목표는 ChatGPT 같은 트랜스 포머 구조 기반의 LLM을 단계적으로 코드로 구현하면서 LLM을 이해하는것.
1.1 LLM이란 무엇인가요?
- LLM은 사람의 텍스트를 이해하고, 생성하고, 응답하도록 고안된 신경망
- 대용량의 텍스트 데이터에서 훈련된 심층 신경망.
- 대규모는 모델의 파라미터 크기와 대량의 훈련 데이터셋을 의미.
- 수천억개의 파라미터를 가짐
- 입력의 다른 부분에 선택적으로 주의를 줄수 있는 트랜스 포머 구조를 활용.
- 생성형 AI 라고 부른다.
AI는 사람 수준의 지능이 필요한 작업을 수행할 수 있는 기계를 만드는 분야
하위 분야로 머신러닝과 딥러닝이 있다.
머신 러닝은 AI 구현에 사용되는 알고리즘을 개발하는데 초점을 맞춘다.
데이터로 학습, 데이터 기반으로 예측, 결정을 내릴수 있는 알고리즘을 개발
전통적 머신러닝은 수동으로 특성을 추출 -> 전문가가 모델을 위해 관련이 높은 특성을 찾고 선택
딥러닝은 머신 러닝의 하위 분야로 3개이상의 층을 가진 신경망을 활용해 데이터에 있는 복잡한 패턴과 추상화를 모델링.
딥러닝은 수동 특성 추출이 필요하지 않다.
1.2 LLM 어플리케이션
- LLM은 비정형 텍스트 데이터(Unstructured text data)를 분석하는 능력이 뛰어남.
- 기계번역, 텍스트 생성, 감성 분석, 텍스트 요약 등에 사용된다.
- ChatGPT, Gemini와 같은 Chatbot, virtual assistant를 구현 가능
1.3 LLM의 구축 단계
직접 만들어보면 메커니즘과 한계를 이해하는데 도움이 된다.
오픈소스 LLM을 특정 도메인의 데이터 셋이나 작업에 적용하기 위해 사전 훈현 하거나 미세 튜닝 하는데 필요한 지식을 갖추게 된다.
특정 도메인에 특화된 커스텀 LLM이 Chat GPT 같은 범용적 LLM보다 성능이 뛰어나다. BloombergGPT, 의료LLM등이 있다.
커스텀 LLM은 개인정보 보호, 작은 규모의 커스텀 LLM은 랩톱이나 마이크로 장치에 바로 배포가 가능. 사용자가 원할때 언제든지 업데이트가 가능
LLM을 개발하는 일반적인 과정은 사전 훈련과 미세 튜닝으로 구성된다.
사전은 대규모 데이터 셋에서 훈련시켜 초기단계를 의미
사전 훈련된 모델을 파운데이션 모델로 사용하여 미세 튜닝을 통해 더 개선이 가능
미세 튜닝은 모델을 구체적 도메인을 위한 특정 데이터 셋에서 훈련하는 과정.
레이블이 없는 원시 텍스트로 사전 훈련을 진행 -> 사전 훈련된 LLM (파운데이션 모델)을 레이블이 있는 데이터 셋에서 추가로 훈련하여 특정 작업에 맞게 미세 튜닝된 LLM을 얻는다.
LLM을 만드는 첫 단계를 원시 텍스트 라고 부르는 대규모 텍스트 말뭉치에서 훈련하는것
원시는 데이터에 레이블 정보가 없는 일반 텍스트 라는 의미.
LLM은 입력 데이터로부터 레이블을 생성하는 자기 지도 학습 방식을 사용한다.
서식문자나 알 수 없는 언어로 된 문서를 제거하는 전처리 가능
사전 훈련을 거친 모델을 베이스 모델, 파운데이션 모델 이라 부른다.
대표적인 예는 GPT 3 이다.
광범위한 훈련 데이터 대신에 몇개의 샘플을 기반으로 새로운 작업을 수행하는 방법을 배우는 퓨샷 학습을 제한적으로 수행 가능
대규모 텍스트 데이터 셋에서 다음 단어를 예측하도록 훈련하여 사전 훈련된 LLM을 얻은 후 레이블이 있는 데이터에서 이 LLM을 추가로 훈련할수 있다. 이를 미세 튜닝 이라 부른다.
미세 튜닝의 종류
지시 미세 튜닝 : 지시와 정답 쌍으로 데이터 셋이 구성 ( 텍스트를 번역하기위한 쿼리와 올바르게 번역된 텍스트) 1대1?
분류 미세 튜닝 : 텍스트와 클래스 레이블로 데이터 셋이 구성된다. ( 이메일과 스팸/스팸 아님) 다대 다?
1.4 트랜스포머 구조 소개
- 대부분의 최신 LLM은 논문 "Attention Is All You Need" 에서 소개된 심층 신경망 구조인 트랜스 포머를 기반으로 한다
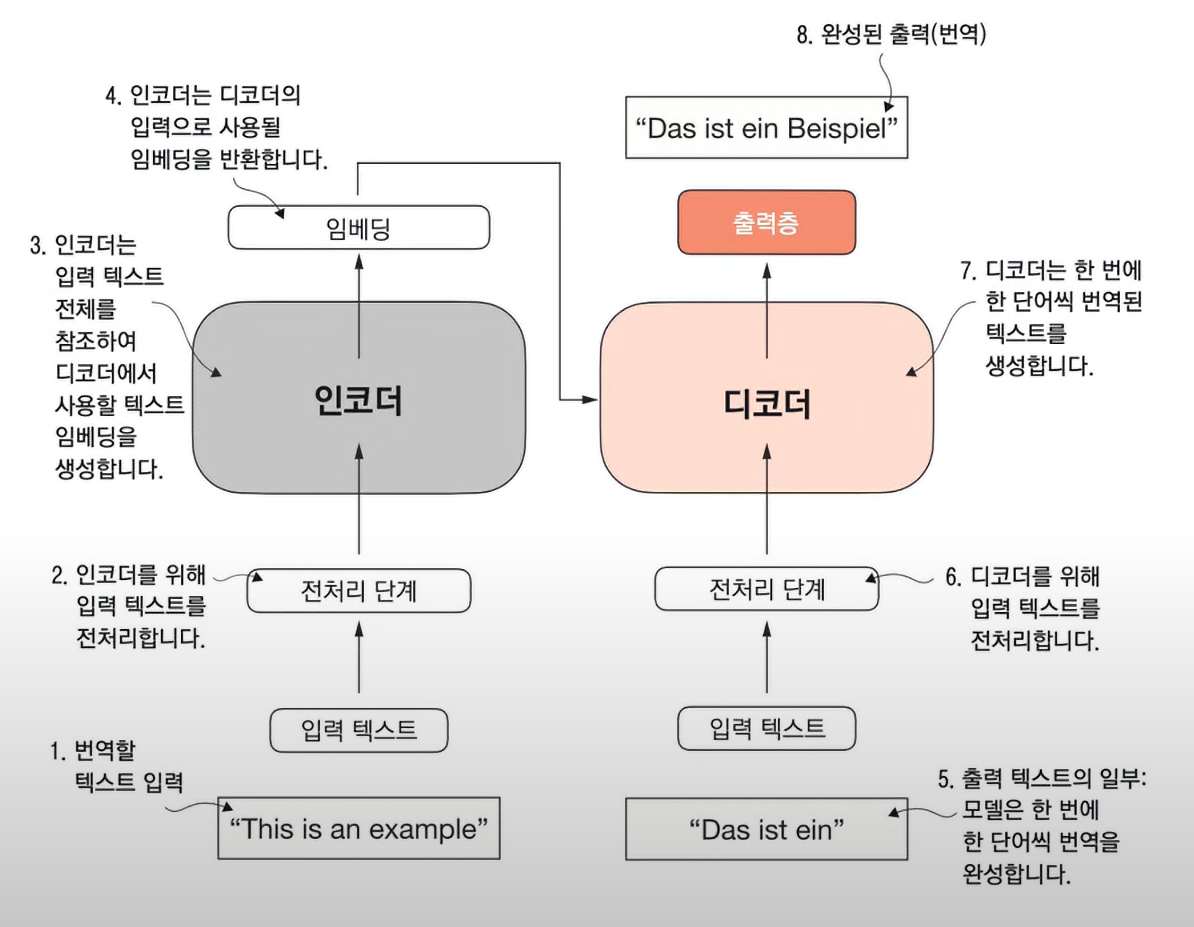
- 트랜스포머 구조는 기계 번역을 위해 고안된 신경망 구조이고 어텐션 메커니즘은 이전에 개발되었다.
- 2개의 서브모듈인 인코더와 디코더로 구성된다.
- 입력된 텍스트는 전처리를 거쳐 벡터화 된후 인코딩을 거쳐 임베딩을 반환하게된다.
- 디코더는 이 벡터를 디코딩하여 입력받은 텍스트를 타깃 언어로 된 텍스트를 생성한다.
- 인코더와 디코더 모두 셀프 어텐션 메커닌즘으로 연결되어있다.
- 트랜스포머와 LLM의 핵심 요소는 셀프 어텐션 메커니즘이다.
- 이를 통해 모델은 시퀀스에 있는 다른 단어나, 토큰에 가중치를 부여할수 있다.
- 이 메커니즘으로 모델이 입력 데이터에서 긴 범위에 걸치 의존성과 맥락 관계를 알수 있다.(추가 설명은 3장에서 진행)
- 디코더는 다음 단어를 예측 하도록 한다
- 단어를 벡터로 생각하는 개념은 처음부터 당연하지 않았다.
- word2vec는 주변에 있는 단어를 예측 하는 것이다.

- 다음 단어를 예측하는 트랜스 포머와 구조가 비슷하다.
- 단어가 가진 어떤 특징이나 역할 문맥을 고정된 크기의 실수 벡터로 표현이 가능하다.
- 핵심은 이코더 모델 디코더 모델이 만드는 단어 벡터이다.
- 인코더만 사용해서 사용하는 것은 최종 결과가 하나의 벡터로 나오는것 분류모델같은 역할이 있다.
- Bert- bidiectional encoder representations from transformers 는 GPT와 훈련 방식이 다르다. 인코딩 모델이기 때문
- 입력된 문장에서 블랭크를 입력하면 인코더를 통해서 누락된 블랭크를 채운다.

- 디코더만 사용하는 모델은 GPT 이다.
- 인코더에서 입력하는것 없이 사용이 가능하다.
- 블랭크부터 시작하면 이상하니 초기텍스트(프롬프트)를 입력해서 시작한다.
- 디코더 기반의 모델을 활용해서 텍스트를 완성 시킨다.

제로 샷 : 처음 보는 작업에 일반화 하는 능력을 의미
퓨 샷 : 사용자가 입력으로 제공한 최소한의 샘플로부터 학습
1.5대규모 데이터셋 활용하기
- 책에서는 교육적인 목적으로 사전 훈련을 위한 코드를 작성하영 LLM을 사전 훈련 할것이다!